<Weeks 1,2> Tesseract Page Segmentation Modes (PSMs) Explained and their relations
The OCR practitioners use the relevant page segmentation mode (psm). The Tesseract API provides several page segmentation modes (default behavior of Tesseract in mode psm 3) if we want to extract a single line, a single word, a single character, or a different orientation. Here is the list of the supported page segmentation modes by Tesseract:
| modes | Descriptions |
|---|---|
| 0 | Orientation and Script Detection (OSD) only. |
| 1 | Automatic page segmentation with OSD. |
| 2 | Automatic page segmentation, but no OSD or OCR. |
| 3 | Fully automatic page segmentation, but no OSD. (Default) |
| 4 | Assume a single column of text of variable sizes. |
| 5 | Assume a single uniform block of vertically aligned text. |
| 6 | Assume a single uniform block of text. |
| 7 | Treat the image as a single text line. |
| 8 | Treat the image as a single word. |
| 9 | Treat the image as a single word in a circle. |
| 10 | Treat the image as a single character. |
| 11 | Sparse text. Find as much text as possible in no particular order. |
| 12 | Sparse text with OSD. |
| 13 | Raw line. Treat the image as a single text line, bypassing Tesseract-specific hacks. |
In the first two weeks (13/6/2022 - 27/06/2022), for each test case, I will try to :
-
Learn how choosing a PSM can be the difference between a correct and incorrect OCR result review the 14 PSMs built into the Tesseract OCR engine.
-
Witness examples of each of the 14 PSMs in action
-
Discover my tips, suggestions, and best practices when using these PSMs
Source code and github Repository
This blog is accompagied by my Kde gitlab resposiory that containes the source code.
The purpose is to facilitate and decode these options into appropriate and relevant choices for the user to understand more easily. The second purpose is to help me design a pipeline of pre-processing image methods to enhance the accuracy and compensate for the constraints of Tesseract.
What Are Page Segmentation Modes?
The “page of text“is significant. For example, the default Tesseract PSM may work well for you if you are OCR’ing a scanned chapter from a book. But if we are trying to OCR only a single line, a single word, or maybe even a single character, then this default mode will result in either an empty string or nonsensical results.
Despite being a critical aspect of obtaining high OCR accuracy, Tesseract’s page segmentation modes are somewhat of a mystery to many new OCR practitioners. I will review each of the 14 Tesseract PSMs and gain hands-on experience using them and correctly OCR an image using the Tesseract OCR engine.
Getting Started
I use one or more Python scripts to review. Setting a PSM in Python is as easy as setting an options variable.
PSM 0. Orientation and Script Detection Only
The psm --0 does not perform OCR directly; at least, we can know the context of the scanned image.
I have constructed some images with different rotations and watched it happen. In this case, we have an original text image like :

Tesseract has determined that this input image is unrotated (i.e., 0◦) and that the script is correctly detected as Latin, as the following output :
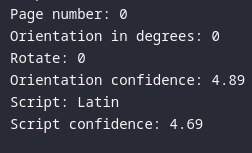
Considering various rotations of this image:

As I can see, the output is correct now with some images rotated with the set of angles in {0, 90, 180, 270} clockwise. With another rotation angle such as 115 or 130 degrees, the orientation in degree is exclusively followed in these fixed orientations and is incorrect for each case.
The orientation and script detection (OSD) examines the input of the image and returns two values :
-
How the page is oriented, in degrees, where
angle = {0, 90, 180, 270}. -
The confidence of the script (i.e., graphics signs/writing system), such as Latin, Han, Cyrillic, etc.
--psm 0 mode as a “meta-information” mode where Tesseract provides you with just the script and rotation of the input image and may help implement pre-processing methods like skew text image.
PSM 1. Automatic Page Segmentation with OSD
For this option, Automatic page segmentation for OCR should be performed, and OSD information should be utilized in the OCR process. I attempt to take the images in figure 1 and pass them through Tesseract using this mode; we can notice that there is no OSD information. Tesseract must be performing OSD internally but not returning it to the user.
Note : The psm 2. Automatic Page Segmentation, But No OSD, or OCR mode is not implemented in Tesseract
PSM 3. Fully Automatic Page Segmentation, But No OSD
PSM 3 is the default behavior of Tesseract. In fact, Tesseract attempts to segment the text and will OCR the text and return it.
PSM 4. Assume a Single Column of Text of Variable Sizes
An exceptional example in this mode is a spreadsheet, table, receipt, etc, where we need to concatenate data row-wise. I assume a small sample which is a receipt from the grocery store, and try to OCR this Image using the default --psm 3 modes:

We can notice the result was not what we expected; in this mode, Tesseract can not infer that we are examining the column data, and the text along the same row should be associated. So let’s see the magic output with the option --psm 4. The result is better:

PSM 5. Assume a Single Uniform Block of Vertically Aligned Text
In this mode, we wish to OCR a single block of vertically aligned text, either positioned at the top of the page, the middle of the page, or the bottom of the page. However, I don’t comprehend and discover any instance corresponding to this model.
In my experiment, psm --5 combines psm --4 and performs well exclusively with a rotated 90◦ clockwise image. For example :

Tesseract can circle the receipt from the illustration overhead, and we retain the more acceptable output :

PSM 6. Assume a Single Uniform Block of Text
The meaning of the uniform text is a single font without any variation pertinent to a type of page of a book or novel.
Passing a page from the famous book The Wind in the Willows in the default mode 3, we see the result below:

We can consider that the output of the image above contains many new lines and white space that make the user take the time to remove them. By using the --psm 6 modes, we are better able to OCR this big block of text, containing fewer errors and demonstrating the correct form of a text page :

PSM 7. Treat the Image as a Single Text Line and PSM 8. Treat the image as a Single Word
For each mode’s name, when we want to OCR a single line in an image or a single word, modes 7 and 8 are suitable. The test case is often the image of the name of a place or restaurant, etc., or a small slogan in a line.
For example, we need to extract the license/number plate license/number plate; this takes time to recover by the user. Considering mode 3, we don’t obtain any result. Otherwise, modes 7 and 8 tell Tesseract to treat the input as a single line or a single word (horizontal on the line) :

PSM 9. Treat the Image as a Single Word in a Circle
I attempt to test and discover the image corresponding to the meaning of Single Word in a Circle, but Tesseract provides the empty or incorrect result. Accordingly, the test case for this model is rare, and we can ignore it.
PSM 10. Treat the Image as a Single Character
When we extract each character, creating an image as a single character is beneficial. I think modes 7 and 8 can work better because a single character can be considered a single word, so we can skip --psm 10.
PSM 11. Sparse Text: Find as Much Text as Possible in No Particular Order
In this mode, Tesseract’s algorithm tries to insert additional whitespace and newlines as a result of Tesseract’s automatic page segmentation. Therefore, for unstructured text (as sparse text ), --psm 11 may be the best choice.
In my experiment, the absolute sample is the table of content, ore menu, etc. The text is relatively parsed and doesn’t stick to a piece of text. Using the default --psm 3, we got the results with several white spaces and newlines. Tesseract would infer the structure of the documentation, but there is no document structure here.

Meanwhile, the input image is sparse text with --psm 11, and this time the results from Tesseract are better :

PSM 12. Sparse Text with OSD
The --psm 12 mode is identical to --psm 11 but now adds in OSD (similar to --psm 0)
PSM 13. Raw Line: Treat the Image as a Single Text Line, Bypassing Hacks That Are Tesseract-Specific
In this case, other internal Tesseract-specific pre-processing techniques will hurt OCR performance, or we can consider that Tesseract may not automatically identify the font face. For example, we have some samples with a different font like :


With the default mode, Tesseract returns an empty output. Otherwise, we have the corresponding results by treating the image as a single raw line of text, ignoring all page segmentation algorithms and Tesseract pre-processing functions.
Conclusion
To facilitate and differentiate between each mode and ignoring another, I would like to divide each mode in terms of the document type.
-
Mode 3 (default) is always a priority to use first for all cases. In the best context, the accuracy of OCR output is high, we have done. On the other hand, we have to decide to modify the configuration.
-
Mode 4 is often used for spreadsheets, tables, receipts… or we need to concatenate data row-wise.
-
Mode 6 is helpful for pages of text whose a single font, such as books, novels, or emails, etc
-
Mode 11 is useful for unstructured text, or sparse text like menus,…
-
Mode 7,8,10, or even 13 is treated image as a single line or a single word with unique fonts or strange characters such as Logo, license plates, label, etc
Based on this exploration, in the next step, I will construct pre-processing methods such as properly skewing image text to the limitation of using the modes, removing shadow, and correcting perspective. The purpose is to create the pipeline for the automatic processing of images for Tesseract; the user can efficiently reduce the choice of modes on Tesseract.