<Weeks 5,6> Plugins Interface components
In the following weeks (June 11, 2022 to July 25, 2022 ), I will try to :
- Make decisions to choose the architecture of the plugin.
- Design UML for each component of the plugin.
- Write documentation.
Frontend:
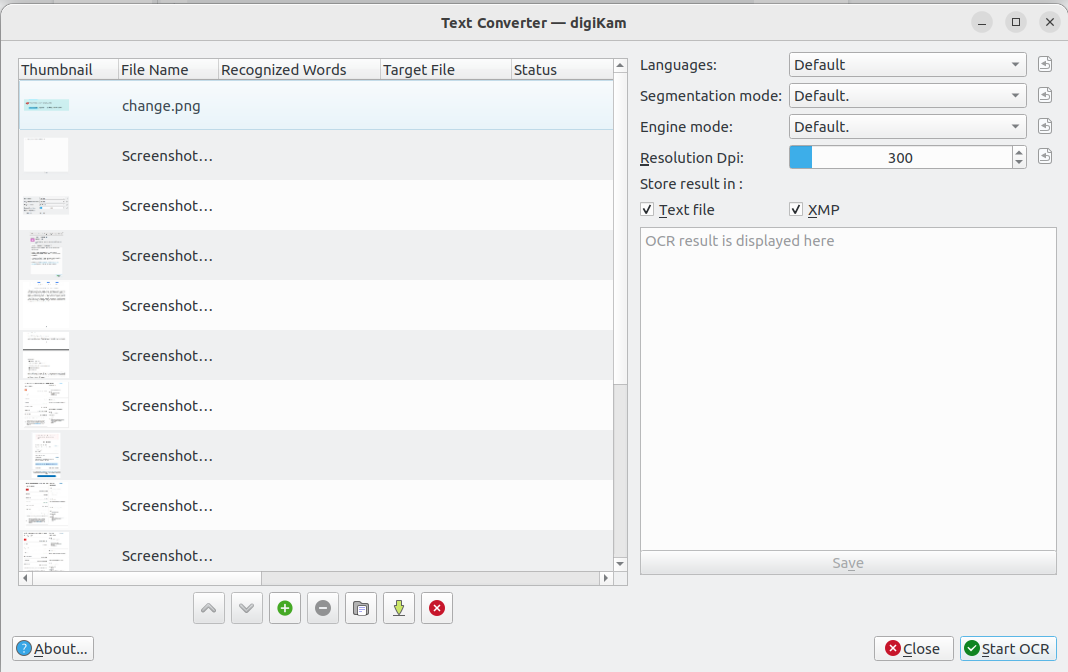
The idea of the OCR processing plugin in digikam is inspired by another plugin used for the conversion from the RAW to the DNG version. The GUI for the batch processing of the plugin, is a dialog, consists of :
The widget list of images to be processed in OCR on the left of the dialog.
On the right side, optional widgets display all the settings components for setting up Tesseract options:
- Language : Specify language(s) used for OCR.
- Segmentation mode : Specify page segmentation mode.
- Engine mode : Specify OCR Engine mode.
- Resolution dpi : Specify DPI for the input image.
A text Editor for visualizing the content of text detected in the image.
A button to save the content in files.
Important link:
I would like to share a single merge request that contains principally all the implementation of the plugin in the Gsoc period :
https://invent.kde.org/graphics/digikam/-/merge_requests/177
Implementation :
First of all, a TextConverterPlugin is created, an interface that contains brief information about the OCR processing plugin. TextConverterPlugin is inherited from the class DPluginGeneric, a Digikam external plugin class whose virtual functions are overridden for the new features.
This object includes methods overriding from the parent class:
| Functions | Descriptions |
|---|---|
| name() | Returns the user-visible name of the plugin, providing enough information as to what the plugin is about in the context of digiKam. |
| iid() | Returns the plugin interface’s unique top-level internal identification property of the plugin interface. In this case, the formatted identification text is a constant substitute token-string like: “org.kde.digikam.plugin.generic.TextConverter” |
| icon() | Return an icon for the plugin supported by QIcon |
| authors() | Return an authors list for the plugin with authors details informations like author ’s names, their emails, copyright year and roles |
| description() | Return a short description about the plugin |
| detail() | Return a long description about the plugin |
| setup() | Create all internal object instances for a given parent. |
The interface is shown like:
Text Converter Dialog
The idea is to set up a dialog widget. There is a dialog box using TextConverterDialog to list the files processed in OCR and a status to indicate the processing.
TextConverterDialog is a DPluginDialog (Digikam defaulted plugin dialog class) that uses QDialogButtonBox, which presents buttons in a layout that conforms to the interface guidelines for that platform, allows a developer to add buttons to it, and will automatically use the appropriate format for the user’s desktop environment. We can see the design of the dialog here:
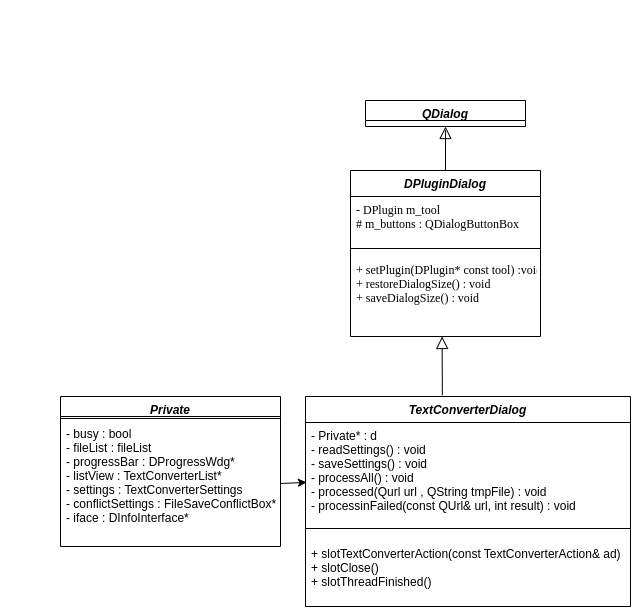
It implements principally a slot TextConverterAction() that uses internal methods and is called to apply OCR processing into the image after pre-processing.
The main dialog consists of all Tesseract options widgets (Text converter Settings) and a text editor to view the OCR result discussed in the following sections.
Text converter Settings
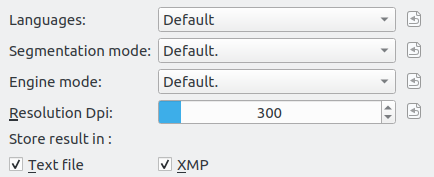
Text Converter Settings object is a widget containing optional widgets displaying all the settings components for setting up Tesseract options for users to select. The main options for these settings are
Three DcomboBox widgets (a combo box widget re-implemented with a reset button to switch to a default item ):
- Page Segmentation mode (psm).
- Specify OCR Engine mode.
- The language or script to use.
One DNumInput an integer num input widget in Digikam using for Tesseract option dpi resolution.
Two QCheckbox for two options for saving OCR Text into separate text files and hosting text recognized by OCR in XMP (Extreme Memory Profile).
TextConverterSettings is a member object of the dialog. Here is a visualization of the OCR settings
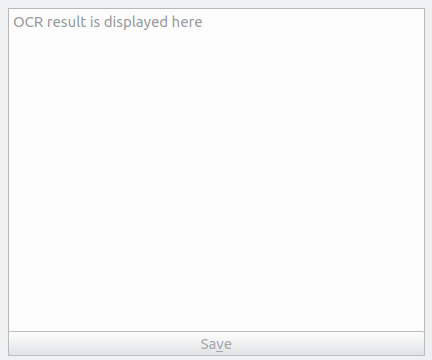
Text Editor
A text Editor for visualizing the content of text detected in the image. A QTextWidget + Sonnet spell checker showing the recognized text from a scanned document. If i select a file from the left side list, the reader is changed accordingly. A text Editor is [DTextEdit which combined these two functionalities.
Text Converter List
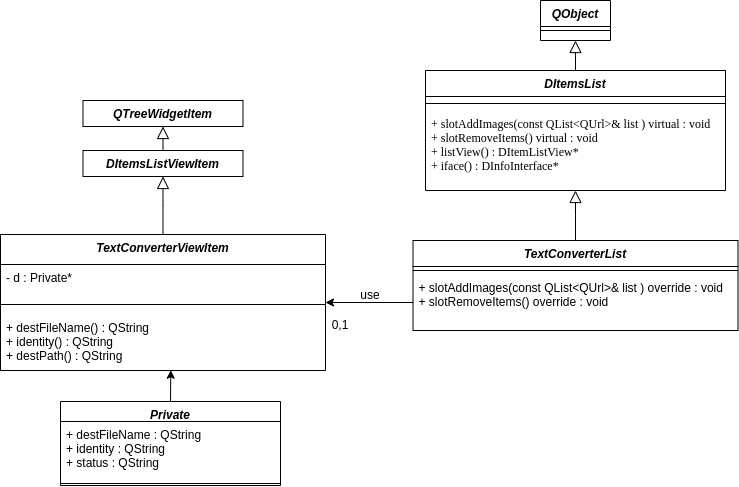
The widget list of images to be processed in OCR, where the urls are pointing to the pictures, is located in a generic list for all plugins based on QTreeWidget. TextConverterList is inherited from DItemList, an abstract item list. TextConvertList composes DItemsListViewItem, which is an interface of Tree widget items that are used to hold rows of information. Rows usually contain several columns of data, each of which can contain a text label and an icon.
Each text converter item consists of 4 specific features:
| Column | Description |
|---|---|
| File Name | a URL pointing to the image. |
| Recognized Words | number of words recognized |
| Target File | a target file that saves converted text from images. |
| Status | an indication during processing. |
Here is a capture of the text convert List widget which I implemented:
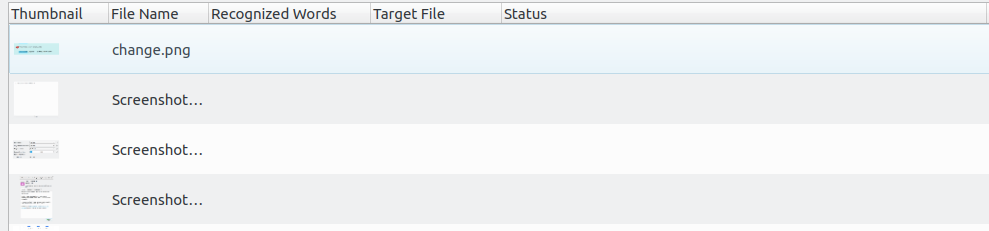
Results
The architecture and the position of each widget components are designed in the following image. This visualization help me more easy to implement:
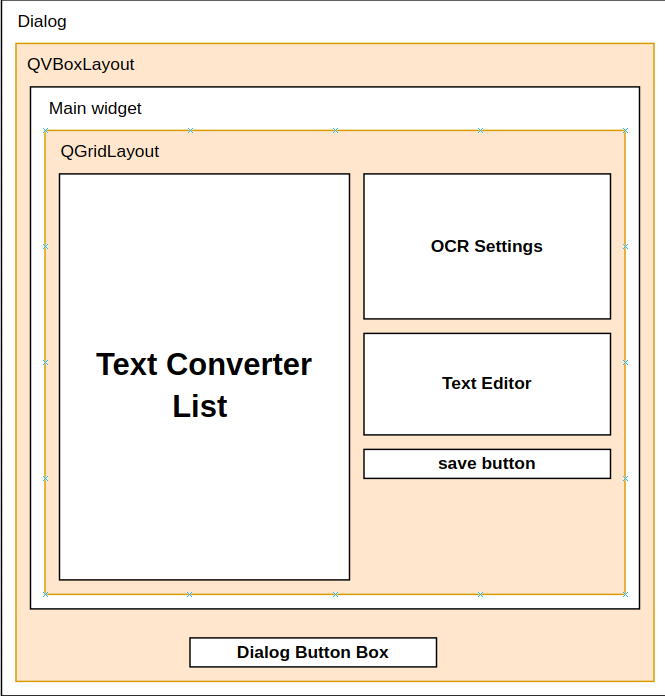
Here is the expected of GUI for the batch processing of the plugin :
Main commits
Next step
In the next few weeks, I will:
- Implement the Ocr Tesseract Engine object used for OCR text from the image.
- Implement an internal multi-thread for OCR processing image.
- Polish and re-implement code if necessary.